Chroń swoje zaplecze - blokowanie niechcianych botów - Ahrefs, MajesticSEO i inne
Każdy porządny pozycjoner chroni swoje cztery litery. Dla każdego pozycjonera najcenniejsze zawsze jest zaplecze, bo pozwala dystrybuować treść oraz linki wspomagające proces linkowania i czasami nawet na siebie zarabia.
Dzisiaj chcę Wam pokazać prosty i przyjemny sposób na blokowanie niechcianych robotów (crawlerów, botów), które skanują naszą stronę pod różnym kątem. Głównym celem jest ograniczenie widoczności dla narzędzi takich jak MajesticSEO i Ahrefs, które pokazują kto i do kogo linkuje.
W sieci można znaleźć przykłady bardzo długich wpisów htaccess, które zawierają najpopularniejsze crawlery oraz te inne. Osobiście uważam, że tworzenie takich wpisów jest bez sensu, bo plik htaccess staje się mniej czytelny. A w takim pliku mogą znajdować inne, dłuższe wpisy np. przyspieszenie strony.
Po pierwsze: olej robots.txt
W plikach typu robots.txt nigdy nie blokuje botów. Przyczyna jest prosta. Nie zawsze jest on respektowany. Dlatego nie tracę czasu na takie zabawy w kotka i myszkę.
Dlatego najlepsza metoda, bo blokowanie z poziomu serwera - czyli plik htaccess.
Blokuj mądrze - daj dostęp tylko wybranym botom
Tak jak pisałem wcześniej, nie ma sensu tworzyć długiej listy, bo wystarczy, że bot zacznie się inaczej przedstawiać (np. inny user-agent) i musimy modyfikować plik - dodając lub edytując odpowiednią linijkę. Nie wspominam już o szukaniu odpowiednich nazw.
U siebie na blogu, jak i innych serwisach, wpuszczam tylko trzy boty: Google, Yahoo, Binga. Reszta nie ma dostępu do strony.
Tak to wygląda w pliku htaccess:
SetEnvIfNoCase User-Agent .*google.* search_robot
SetEnvIfNoCase User-Agent .*yahoo.* search_robot
SetEnvIfNoCase User-Agent .*BingBot.* search_robot
SetEnvIfNoCase User-Agent .*Mozilla.* search_robot #przeglądarki
Order Deny,Allow
Deny from All
Allow from env=search_robotRaptem kilka linijek :). Osobiście uważam, że jest to bardzo zgrabne rozwiązanie.
Aktualizacja: Dzięki Damianowi, okazuje się, że trzeba jeszcze dodać jedną regułkę by wpuszczać przeglądarki. Na moim serwerze działa to poprawnie, jednak na innych będzie rzucało błędem 403.
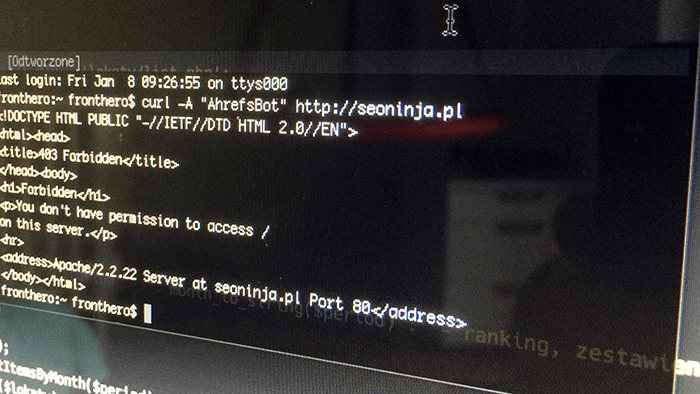
Oczywiście możemy sprawdzić to czy wszytsko działa poprawnie. Można to zrobić za pomocą curl. Poniżej kod do sprawdzenia czy bot Ahrefs będzie miał dostęp do naszej strony.
curl -A "AhrefsBot" http://seoninja.plWtedy w odpowiedzi dostaniemy informację o braku dostępu do strony - czyli błąd 403.
Gdyby ktoś szukał, to boty Ahrefs i MajesticSEO przedstawiają się następująco:
Ahrefs: (compatible; AhrefsBot/2.0; +http://ahrefs.com/robot/)
MajesticSEO: (compatible; MJ12bot/v1.4.0; http://www.majestic12.co.uk/bot.php?+)Blokowanie botów na serwerach nginx
Aktualizacja: W komentarzach pojawiła się wersja dla nginx. Nie testowałem tego. Poniżej ładnie sformatowany kod.
http {
map $http_user_agent $bad_bot {
default 1;
~*^google 0;
~*^yahoo 0;
~*^BingBot 0;
~*^Mozilla 0;
~*^Googlebot 0;
}
}Następnie do bloku server dopisać - dla konkretnych stron:
server {
if ($bad_bot) {
return 444;
}
}Dzięki Piotr za wersję dla nginx.

Komentarze 36
Ale dodanie tych trzech linijek zablokuje dostęp dla wszystkich oprócz tych trzech wymienionych botów. Naa Twojego bloga można wejść bez problemu więc musi być tam coś jeszcze :)
@Damian: tą samą regułkę mam na stronach z WP. Dodałem ją do innych, domyślnych regułek w htaccess jakie tworzy WP. I też ładnie śmiga.
Niemożliwe, reguła mówi jasno zablokuj dla wszystkich i wpuść tylko zdefiniowane boty
@Damian: sprawdzałeś u siebie?
dokładnie jak pisze Damian, po wpisaniu tych trzech zasad stronę mogą pobrać użytkownicy przedstawiający się jako google, yahoo lub bingbot. Ĺťeby działało dla normalnego użytkownika trzeba dodać kolejne regułki puszczające user-agent przedstawiające się jako firefox, chrome itp.
Każdy kij ma dwa końce tj. nie podajemy długich list kogo blokujemy za to podajemy listę kogo puszczamy.
Uznając iż dostęp użytkowników do strony jest ważniejszy to rozważniej jest jednak blokować niechcianych niż dopisywać chcianych.
Podsumowując nawet odblokowując konkretnych agentów, to i tak nie mamy pewności czy jakiś bot nie przedstawi się jako firefox lub chrome.
Oczywiście, przy próbie wejścia na stronę błąd 403.
Dopiero po dopisaniu:
SetEnvIfNoCase User-Agent .*chrome.* search_robot
wchodzę bez problemu.
@Damian: miałeś rację. Okazuje się, że mój serwer ma jeszcze dodatkową konfigurację, która wpuszcza przeglądarki. Zaktualizowałem wpis o dodatkową linijkę:
SetEnvIfNoCase User-Agent .*Mozilla.* search_robot #przeglądarki
Dzięki za ten wpis. I dzięki za szybką poprawkę. Na moim serwerze też rzucało błędem. Teraz wszystko śmiga!
Dobry patent. Inne niż wszystkie. Na pewno wykorzystam na moich stronach i zapleczach. Ktoś wie ile czasu trzeba by ahrefs i majesticseo zaktulizował swoje dane i nie pokazywał moich stron po dodaniu tych regułek?
to ja od siebie dorzucę ustawienia dla nginx:
do bloku dopisać http:
http {
map $http_user_agent $bad_bot {
default 1;
~*^google 0;
~*^yahoo 0;
~*^BingBot 0;
~*^Mozilla 0;
~*^Googlebot 0;
}
}
do bloku server dopisać - dla konkretnych stron:
server{
if ($bad_bot) {
return 444;
}
}
ustawienia te powodują po wpisaniu curl -A "AhrefsBot"
zwracanie curl: (52) Empty reply from server
Podałeś wpis dla przeglądarki mozilla, jak będą wyglądać wpisy dla pozostałych przeglądarek dostępnych na rynku? Dobrym rozwiązaniem byłoby je również uwzględnić. Z tego co rozumiem, podany kod blokuje nie tylko pozostałe boty ale również wszystkie przeglądarki poza mozillą.
@Dawid - ta regułka działa dla wszystkich przeglądarek :)
SetEnvIfNoCase User-Agent .*Mozilla.* search_robot #przeglądarki
tak przedstawia się większość przeglądarek (ie, chrome, mozilla)
dodać warto user-agenty dla cms - wp, drupal...
drupal przy tej konfiguracji komunikuje błędy
@Piotr: dzięki za wersję dla ngix. Późnym wieczorkiem zaktualizuję wpis :)
I wszystko jasne. :)
Ale w sumie jeśli zaplecze jest tylko pod linki to po co wpuszczać przeglądarki? Wystarczy wpuścic tylko te 3 boty mamy pewność że konkurencja go nie prześwietli ;)
@Sebastian: w sumie, to masz rację :). Pomijając regułkę dla przegladarek nikt nie wejdzie na stronę. Dobrze kombinujesz.
Naprawdę przydatne porady! Jestem dopiero na początku swojej drogi z pozycjonowaniem- taka wiedza mi się przyda.
Ten wasz kod jest mocno dziurawy. Bo to nie prawda że wpuści tylko google, binga i yahoo! Dodając na końcu Mozilla pozwalacie na wejście masie robotom np.
Chiny:
"Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"
Rosja:
"Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)"
itd.
Sporo tego jest. Mocno zasobożernych.
Czy ten wpis musi być jakoś otagowany? Można go wklieć po: # END WordPress ??
M@K - masz jakieś rozwiązanie na tych zasobożernych?
Byc moze glupie pytanie, ale czy kiedy edytuje .htaccess, to "# END WordPress" musi byc zawsze na samym koncu dokumentu?
P.S. wielkie dzieki za ten genialny blog!
Pozdrawiam
Podany przykład blokuje też mechanizmy facebook odpowiedzialne za meta tagi Open Graph. Problem pojawia się podczas udostępniania np: artykułów z bloga na facebook.
Według mnie, lepszym rozwiązaniem jest jednak blokada poszczególnych botów niż tworzenie tego typu "białej listy" ;)
Blokując każdego bota z osobna może mamy więcej linijek, ale za to jest większe pole manewru. Na Wordpressie ciekawą opcją jest "czarna lista" z wtyczki iThemes Security (dawne WP Better Security), która automatycznie dodaje blokadę wielu szkodliwych botów do pliku .htaccess ;)
U mnie działa ale nie wiem czy na 100% to dobry sposób.
Ale warto zabezpieczyć jeszcze tak:
SetEnvIfNoCase User-Agent "^libwww-perl*" block_bad_bots
Deny from env=block_bad_bots
Choć prawdę mówiąc ogólnie blokowanie, zezwalanie to coś do czego podchodzę z pewnym dystansem żeby sobie nie zrobić jeszcze gorzej.
A jak odblokować robota facebooka? Bo pokazuje mi 403 jak dodaje dany url na FB
Ktoś powiedział mi że mam zablokowane crowlery na stronie i nie można przez to sprawdzić profilu linków... Czy mogę prosić o pomoc jak to sprawdzić?
Dobra regułka ja ją stosuję razem z regułką która blokuje wybrane boty, na górze w pliku mam regułkę która blokuje wybrane boty a pod nią regułkę która wpuszcza wybrane i blokuje wszystkie inne.
Witam SeoNinję. Czy opisana tu blokada na niechciane boty jest wciąż aktualna? Bo już 2 lata minęły.
Jak przepuszczać boty Facebooka?
Co dopisać w .htaccess ?
Świetny poradnik, dopiero Twój sposób zadziałał nie wiedzieć czemu odwrotnie czyli jak dawałem listę niechcianych nie działał, dziwne, dołączam się do pytania czy są ew. inne boty, które chcemy dopuścić.
Ja mam problem odnoście blokowania botów, z tej strony iż powodują one zbyt dużą ilość zapytać do serwera, czy ta formuła powinna pomóc?
u mnie mino dodania ostatnie linijki o przeglądarkach i tak wyskakuje błąd 403
Zastosowałem, działa tylko jest problem z WordPressem a dokładnie z dodawaniem obrazków do artykułów. Są wrzucane, ale się nie wyświetlają na podglądzie. Gdy blokowanie w htacces wyłączam obrazki się ładują. Potem gdy znowu blokadę włączam obrazki .. dalej są!
ktoś wie jak to obejść?
Ja wyszukuję boty z access logów:
zgrep -a 'bot' /home/www/logs/*.tar.gz | awk '
{
if ($9 == 200 OR $9 == 404) {
print $12
}
}
' >> /home/www/uniqueBots
sort -u -o /home/www/uniqueBots /home/www/uniqueBots
cat /home/www/uniqueBots
wc -l /home/www/uniqueBots
nastepnie przeglądam co tam wpadło i dopisuję manualnie do listy, powyższe zależne od formatu Waszego access log'a (czyli kolumny mogą być przestawione oraz położenie plików - wiadomka)
Zastanawiam się nad odwrotną stroną czyli dopuszczanie wg. znanych środowisk, ale to może kiedyś urwać głowę SEO, więc chyba na tym poprzestanę. Słowo 'bot' można jeszcze zamienic na 'crawler' zawsze wpada coś więcej ;)
.*mozilla.*
to regex, wpusci wszystko co ma wsrodku mozilla,a z przodu czy z tylu moze byc np AhrefsBot. wiec wpusci ahrefsbota.
Teraz kazdy bot ma w sobie useragenta mozilli z dopiskiem nazwy serwisy/firmy np costam mozilla costam ahrefsbot costam.
wiem bo sam padlem ofiara tego.
juz inna sprawa, ze majestic prawdopodobnie uzywa samego useragenta mozilli (po cichu) przez co znalazl mi 20 linkow, i pewnie nie on jeden.
wychodzi ze tier 1 powinien byc maly i nie banowalny